摘要:这节课我们接着上节课的内容,继续学习requests之破解百度翻译案例。我们上节课已经知道了解题思路,这节课我们来看看代码怎么写。1.首先导入requests模块2.获取请求类型以及网址信息通过页面信息(如下图)可知,百度翻译的请求类型是p...
这节课我们接着上节课的内容,继续学习requests之破解百度翻译案例。我们上节课已经知道了解题思路,这节课我们来看看代码怎么写。

通过页面信息(如下图)可知,百度翻译的请求类型是post类型,并且我们获取到了网页的URL

但是我么通过查看网址知道,并不全,需要参数信息进行补充,我们通过网页获取到参数(如下图)

通过上一步骤我们获取到了data,URL,类型为post,以及headers,便可书写如下代码:
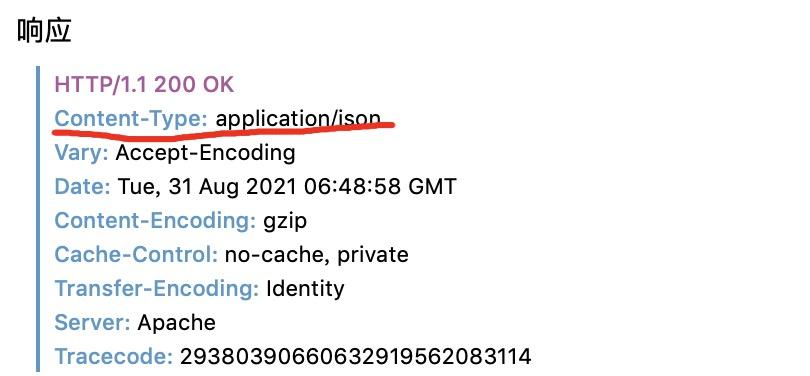
通过代码信息我们可以知道,响应类型信息为JSON类型,而非前几节课讲的text文本格式,因此我们需要先导入JSON,然后通过JSON获取网页的内容(如下图)
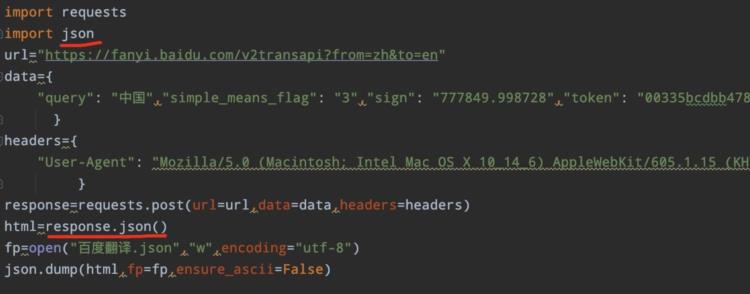
JSON格式保存与text,还是有差别的,按照下面代码直接照猫画虎即可。

这是我们这个练习的完整代码,大家可以试着运行一下,我们会发现使用requests模块,我们需要判断请求类型(post/get),然后根据类型选择参数(data/params),再接着我们根据相应的类型(text/Json),获取到网页信息,最后再保存数据信息即可。
了解更多


